inventory visibility and counting operator experience
An alert finally fires. By then the shrink is already done. The count has been wrong for days. The manager opens the reconciliation screen and finds the gap. The gap was there before anyone knew to look.
What went wrong is not the count. What went wrong is that the threshold was set wrong from day one, calibrated for "normal" loss rather than the acceptable loss the business can actually tolerate. No one adjusted the alert setting. No one rechecked the tolerance. The system was recording correctly. It was alerting incorrectly. And the inventory visibility gap only becomes visible at the exact moment it is too late to act.
Implementation note: The patterns described in this article reflect observations from implementations where operators have encountered these specific inventory alignment gaps. Each scenario corresponds to a real situation mapped during onboarding or remediation engagements.
Why your shrink alerts fire after the damage is done
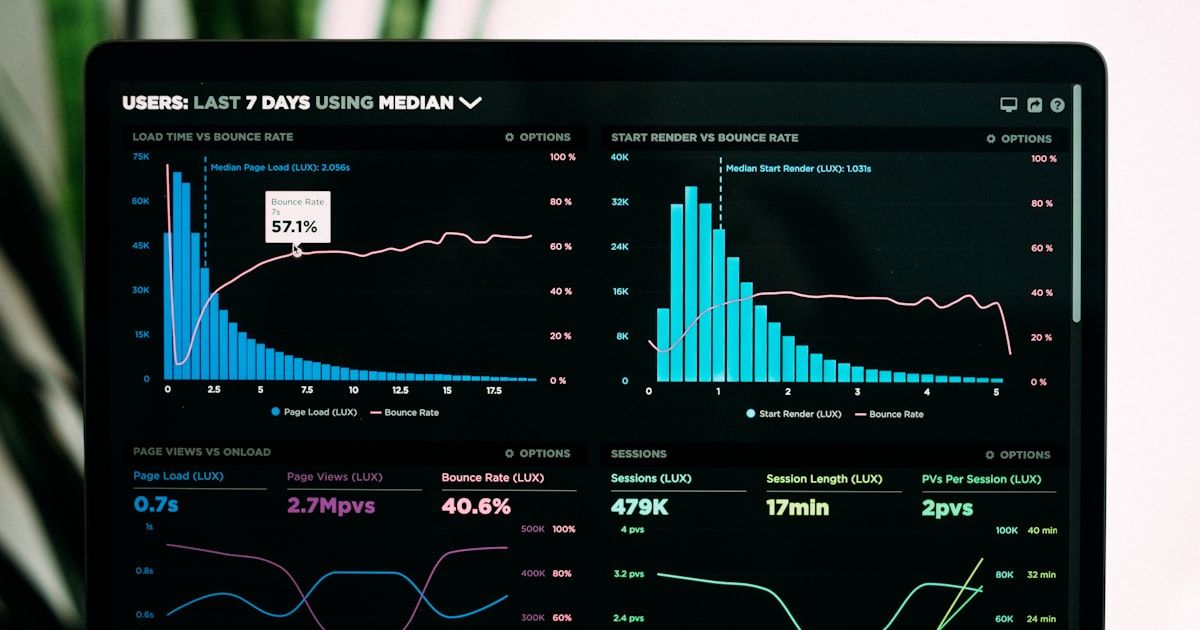
Shrink alerts fire after the damage is done because default alert thresholds are set at aggregate levels that require large variance before triggering, not at levels calibrated to your business's actual shrink tolerance. In most POS, WMS, and ERP platforms, the threshold that determines when an alert fires was never adjusted after initial setup. It sits at whatever the vendor configured for a generic retail environment.
Across implementations we have supported, operators describe the same pattern: the system records transactions accurately, the daily logs look clean, and then a physical count surfaces a gap that has been building for weeks. The alert never fired because the variance never crossed the threshold. The variance stayed below the trigger level while accumulating silently across multiple system records.
A system configured to alert on a 15-unit variance will not fire on a 3-unit discrepancy, a 5-unit count error, and a 4-unit receiving gap happening simultaneously across three separate system records. At the aggregate level, those numbers cancel out or stay below the trigger. At the individual transaction level, each one is real loss. The alert fires when the aggregate threshold is crossed, which is weeks after the first unit went missing.
NRF research found that inventory visibility gaps cost retailers millions annually in untracked shrink, much of it accumulating silently before any alert fires.
What fragmented POS, WMS, and ERP alignment costs operators every week
Fragmented POS, WMS, and ERP alignment costs operators time each week because no single system provides an authoritative inventory figure, and staff spend hours investigating discrepancies instead of running operations. The cost is not measured in shrink alone. The cost is measured in staff hours redirected from value-generating work to reconciliation investigation.
A typical week in a fragmented retail operations stack looks like this: the WMS shows 847 units of a SKU. The POS database shows 839. The ERP expected receipt shows 850. The manager does not know which number is authoritative.
Staff are pulled off other tasks to run a handheld scanner count. The handheld scanner was last synced four hours ago. The count comes back at 841. No one is certain if that is better or worse.
According to Retail Info Systems research, retailers with fragmented systems spend up to 30% more time on inventory reconciliation than operators with integrated stacks.
The manager then spends time in three separate screens trying to identify which system drifted, when, and why. This is not a one-time event. It is a recurring pattern. It happens multiple times per week, every week, for operators who have not established a reconciliation layer between their systems. The time spent investigating the discrepancy is time not spent on receiving, merchandising, staff development, or customer-facing work.
In our implementation experience, operators running three or more systems without a defined reconciliation layer report a persistent weekly drag on manager time that does not show up in the P&L shrink line. It shows up in overtime, in manager fatigue, and in the quiet acknowledgment that inventory issues seem to always be present.
The core issue is not that the systems cannot produce a correct number. The issue is that no one has established which number is authoritative, or built the reconciliation logic that surfaces variance before it compounds. This is the POS WMS ERP inventory alignment gap that shows up in every fragmented stack until the integration sequencing is addressed.
Why 'functional' inventory systems still miss the alert window
Functional inventory systems miss the alert window because recording accuracy and alerting accuracy are distinct functions, and most operators assume a system that logs transactions accurately will also flag variance when it occurs. This assumption is incorrect. A POS that logs every sale accurately can still fly blind on variance if the alert threshold was left at the default configuration.
When incremental drift happens, a 2-unit discrepancy here, a miscounted receiving entry there, nothing triggers. The system records it as normal variance. The next physical count, when it finally happens, reveals the accumulated gap. Operators call this "the big inventory surprise": a count that surfaces losses that happened gradually, invisibly, over weeks.
The alert did not fire because the threshold required a large, obvious anomaly. Incremental, cross-system drift does not look like a large anomaly from inside any single system. It only looks large when you finally count.
This is the gap most operators do not know to look for. The absence of an alert feels like confirmation that inventory is healthy. The system has not flagged anything, so nothing must be wrong. That logic holds until the next physical count surfaces what the system should have flagged weeks earlier.
According to Harvard Business Review research on inventory management, companies with real-time inventory visibility report 20-30% fewer stockouts and significantly lower shrink rates compared to those relying on periodic physical counts.
Inventory units-of-measure drift creates a structurally similar blind spot. When each system uses a different UOM standard for the same SKU, the reconciliation layer silently fails and the gap accumulates before any alert fires, as covered in inventory units-of-measure and checkout UOM drift.
The fix sequence: alert logic before audit
The correct fix sequence starts with alert logic calibration, not physical counting. Most operators follow this sequence when they discover a shrink problem: run a physical count, identify the gap, investigate which system was wrong, adjust the number, move on. Then the next cycle repeats the same delay.
The correct sequence is different:
- Alert logic first — establish what should trigger a notification, at what variance level, and for which SKU thresholds. Without this, every count is discovery instead of confirmation.
- Threshold calibration — set alert thresholds to the business's actual acceptable shrink tolerance, not the system's default aggregate assumption. What loss level is acceptable before an alert fires? Calibrate to that number.
- POS/WMS/ERP reconciliation — map which system is authoritative for which data point and build the reconciliation logic that surfaces variance before it compounds. Which system "owns" the inventory record for each SKU category?
- Physical count cadence — set the cycle count schedule that confirms the alert logic is working, not one that replaces it. Counts should verify the system, not discover problems the system should have flagged.
Most operators start at step four and never loop back to step one. That is why the same blind spots recur. Fix the alert layer first. Everything else becomes confirmation, not discovery.
What does threshold calibration look like in practice? SKU-level thresholds typically start at a percentage of average weekly sales volume for the category. A SKU moving 100 units per week might have a threshold set at 2–3% variance before alert, while a high-value item moving 10 units per week might trigger at 1 unit. These are starting points, not fixed rules. Calibration requires reviewing actual shrink history by category, adjusting for supplier lead time variability, and testing alert response time against manual count results.
How long does alert calibration take? In our implementation experience, a single-location operator with a defined POS and WMS can complete initial threshold calibration in a structured half-day session. The work is not technically complex. It requires reviewing historical shrink data, setting category-level thresholds, and establishing a review cadence to adjust as loss patterns change.
Where the Integration Foundation Sprint fits
The Integration Foundation Sprint fixes inventory visibility as a systems integration problem, not a software selection problem. Most operators do not need a new inventory platform. They need the platforms they already have to produce a single, authoritative version of the truth, and to alert on variance before it crosses a business-calibrated threshold.
The Integration Foundation Sprint maps where your POS, WMS, ERP, and handheld scanning devices are misaligned. It establishes alert logic calibrated to your actual business tolerance, not default thresholds designed for an average operation. It identifies which data handoffs are failing silently and which system should be the system of record for each inventory event.
This is not a software audit. It is not an ERP configuration review. It is an integration sequencing sprint that addresses the root cause of the late-fire pattern. The alert threshold was never set correctly, and the systems underneath it were never reconciled to produce a single accurate number in real time.
The same principle applies across related inventory visibility and counting challenges. Inventory units-of-measure drift, where each system uses a different UOM standard for the same SKU, creates a structurally similar blind spot. That pattern and its fix sequence are documented in inventory units-of-measure and checkout UOM drift. See also the Demand Forecasting Field Guide on alert threshold calibration for how this applies to replenishment alerts, and Shipping and Logistics Operations for cross-system handoff gaps in adjacent workflows.
For operators running AI Automation Services or broader omnichannel stacks, the same sequencing applies.
Alerts fire after the loss, not before — because the threshold was never fixed
The sequence is clear. The technology is already in place. The systems most operators are already running — POS, WMS, ERP, handheld scanners — can produce real-time visibility if they are configured to talk to each other and calibrated to alert on variance that matters to the business, not variance that only matters when it is large.
Operators who fix the alert logic first spend less time auditing. They run counts to confirm the system is working, not to discover what went wrong. The difference between reactive and proactive inventory operations is almost always the alert layer, not the count layer.
Ready to fix the foundation? The Integration Foundation Sprint maps your inventory stack and fixes the alert gaps that cost you every week. Book a discovery call.
FAQ
Why do shrink alerts fire after the loss has already happened instead of before it?
Shrink alerts fire after loss because the alert threshold was set at an aggregate level that requires large variance before triggering, not at a level calibrated to catch incremental drift. The threshold determines the trigger point, and if that trigger point is above the accumulation rate of your actual shrink events, the alert will never fire until a physical count surfaces the gap. The threshold was calibrated for "normal" loss in a generic retail environment, not for the specific loss profile of your operation.
What is the right way to set inventory alert thresholds, and where do operators typically start?
The right way to set inventory alert thresholds is to base them on your business's actual acceptable loss tolerance by SKU category, not on system defaults. Start by reviewing historical shrink data by category over the past twelve months. Identify what variance level is normal for each category and where your tolerance threshold should sit. A typical starting point is a percentage of average weekly sales volume: a SKU moving 100 units per week might trigger at 2–3% variance, while high-value items trigger at 1-unit variance. Then calibrate the threshold so the alert fires before the accumulated gap becomes material to your P&L, not after it is already visible.
How does POS, WMS, and ERP misalignment create invisible shrink that no single system can detect?
POS, WMS, and ERP misalignment creates invisible shrink because each system records inventory events independently without real-time reconciliation. When a discrepancy occurs in one system, the other systems continue to reflect the pre-discrepancy state. A 3-unit discrepancy in the POS, a 2-unit receiving miscount in the WMS, and an unreconciled return do not add up to an alert from any single system. They only accumulate. The aggregate variance stays below the alert threshold in each individual system. The gap only becomes visible when a physical count is run and compared against all three systems at once. No single system sees the full picture until the count happens.
Why does my inventory system say everything is fine but I am still losing product?
Your system has recording accuracy without alerting accuracy. The system correctly logs every transaction, but the alert threshold was left at the default setting, which requires large variance to trigger. Incremental shrink events stay below the threshold and never trigger an alert. The system records everything accurately while flying blind on variance. The gap only becomes visible when a physical count reveals what the system should have flagged. This is the functional-but-broken state that most operators do not discover until a scheduled count surfaces the accumulated loss.
How is the Integration Foundation Sprint different from an ERP audit or a software review?
The Integration Foundation Sprint focuses on data alignment and alert calibration across your existing stack, not on ERP configuration review or software selection. An ERP audit examines system settings and module configurations. A software review evaluates whether to replace a platform. This sprint examines the integration points between POS, WMS, ERP, and handheld scanners to identify where inventory events are being recorded differently across systems, which data handoffs are failing silently, and which system should be authoritative for each inventory event type. The output is a calibrated alert layer and a defined reconciliation sequence, not a configuration report.
*This article is part of the TkTurners field guide series on omnichannel systems integration. For related operator-experience articles, see Demand Forecasting and Replenishment Operations on alert threshold calibration and Shipping and Logistics Operations on cross-system handoff gaps.
Turn the note into a working system.
TkTurners designs AI automations and agents around the systems your team already uses, so the work actually lands in operations instead of becoming another disconnected experiment.
Explore AI automation servicesShahzaib
Systems Integration Specialist
Shahzaib focuses on systems integration, data handoffs, and operational cleanup for TkTurners projects where disconnected tools slow execution.
Relevant service
Explore AI automation services
Explore the service lane